Jak zoptymalizować strony pojedynczej strony dla wyszukiwarek
Kiedy Google i inne wyszukiwarki indeksują witryny, nie uruchamiają JavaScript. Wygląda na to, że strony z pojedynczą stroną - z których wiele opiera się na JavaScript - mają ogromną wadę w porównaniu do tradycyjnej strony internetowej.
Nie bycie w Google może łatwo oznaczać śmierć firmy, a ta trudna pułapka może skusić niedoinformowanych do porzucenia pojedynczych stron w ogóle.
Jednak strony z jedną stroną mają przewagę nad tradycyjnymi stronami w optymalizacji pod kątem wyszukiwarek (SEO), ponieważ Google i inni uznali to wyzwanie. Stworzyli mechanizm dla witryn z jedną stroną, aby nie tylko indeksować strony dynamiczne, ale także zoptymalizować strony specjalnie pod kątem robotów.
W tym artykule skupimy się na Google, ale innych dużych wyszukiwarkach takich jak Yahoo! i Bing obsługują ten sam mechanizm.
Jak Google indeksuje witrynę z jedną stroną
Gdy Google indeksuje tradycyjną witrynę internetową, jej robot indeksujący (zwany Googlebot) najpierw skanuje i indeksuje zawartość URI najwyższego poziomu (na przykład www.myhome.com). Gdy to się zakończy, wówczas podąża za wszystkimi linkami na tej stronie i indeksuje również te strony. Następnie następuje linki na kolejnych stronach i tak dalej. W końcu indeksuje całą zawartość witryny i powiązanych domen.
Gdy Googlebot próbuje zindeksować pojedynczą stronę strony, wszystko, co widzi w kodzie HTML, jest pojedynczym pustym kontenerem (zwykle jest pustym znacznikiem div lub body), więc nie ma niczego do zindeksowania i nie ma linków do przeszukiwania, i odpowiednio indeksuje witrynę ( w okrągłym "okrągłym" folderze na podłodze obok biurka).
Gdyby to był koniec historii, byłby to koniec stron pojedynczej strony dla wielu aplikacji internetowych i stron. Na szczęście Google i inne wyszukiwarki zdały sobie sprawę z ważności witryn z jedną stroną i dostarczonych narzędzi, które umożliwiają programistom dostarczanie robotowi wyszukiwania informacji, które mogą być lepsze niż tradycyjne strony internetowe.
Jak sprawić, by strona pojedyncza strona mogła się indeksować
Pierwszym kluczem do zindeksowania naszej strony z pojedynczą stroną jest uświadomienie sobie, że nasz serwer może stwierdzić, czy żądanie jest robione przez przeszukiwacza, czy przez osobę korzystającą z przeglądarki internetowej i odpowiednio reagować. Kiedy naszym gościem jest osoba korzystająca z przeglądarki internetowej, odpowiedz jak zwykle, ale w przypadku robota zwróć stronę zoptymalizowaną, aby pokazać robotowi dokładnie to, co chcemy, w formacie, który robot może z łatwością odczytać.
Na stronie głównej naszej witryny, jak wygląda strona zoptymalizowana pod kątem robota? To prawdopodobnie nasze logo lub inny główny obraz, który chcielibyśmy pojawić się w wynikach wyszukiwania, tekst zoptymalizowany pod kątem SEO, wyjaśniający, czym jest lub jest strona, oraz lista linków HTML tylko do tych stron, które Google chce zindeksować. Strony nie zawierają żadnej stylów CSS ani skomplikowanej struktury HTML zastosowanej do tej strony. Nie ma też żadnych skryptów JavaScript ani linków do obszarów witryny, których nie chcemy, by Google indeksował (np. Strony z notami o odpowiedzialności prawnej lub inne strony, na których nie chcemy, aby użytkownicy przechodzili przez wyszukiwarkę Google). Poniższy obrazek pokazuje, jak strona może być prezentowana przeglądarce (po lewej) i robotowi (po prawej).
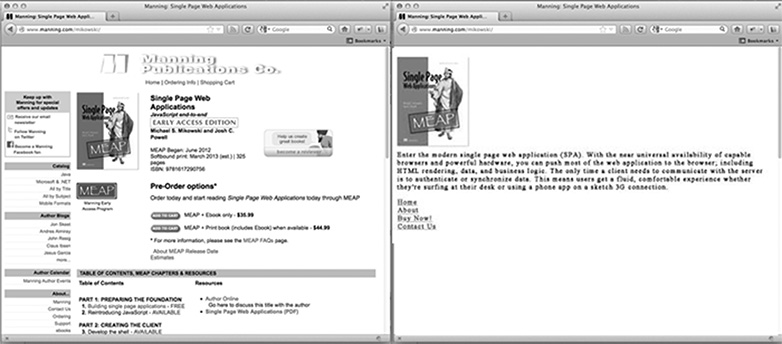
Dostosowywanie zawartości dla robotów indeksujących
Zazwyczaj strony pojedynczej strony prowadzą do różnych treści za pomocą hasza (#!). Te linki nie są traktowane w ten sam sposób przez ludzi i roboty.
Na przykład, jeśli w naszej pojedynczej witrynie link do strony użytkownika wygląda jak /index.htm#!page=user:id,123 , robot będzie widział #! i wiedzieć, aby szukać strony internetowej z URI / index.htm?_escaped_fragment_=page=user:id,123 . Wiedząc, że robot będzie podążał za wzorcem i szukał tego identyfikatora URI, możemy zaprogramować serwer, aby odpowiedział na to żądanie za pomocą migawki HTML strony, która normalnie byłaby renderowana przez JavaScript w przeglądarce.
Ta migawka zostanie zindeksowana przez Google, ale każdy, kto kliknie na naszą wizytówkę w wynikach wyszukiwania Google, przejdzie do /index.htm#!page=user:id,123 . Pojedyncza strona JavaScript strony przejmie stamtąd i wyrenderuje stronę zgodnie z oczekiwaniami.
Dzięki temu twórcy witryn z jedną stroną mają możliwość dostosowania swojej witryny specjalnie do Google, a konkretnie do użytkowników. Zamiast pisać tekst, który jest zarówno czytelny, jak i atrakcyjny dla osoby i zrozumiały dla przeszukiwacza, strony można zoptymalizować dla każdego bez obawy o inne. Ścieżkę robota w naszej witrynie można kontrolować, co pozwala nam kierować użytkowników z wyników wyszukiwania Google na określony zestaw stron początkowych. Będzie to wymagało więcej pracy ze strony inżyniera, ale może przynieść spore zyski pod względem pozycji wyników wyszukiwania i utrzymania klientów.
Wykrywanie robota sieciowego Google'a
W chwili pisania tego artykułu Googlebot ogłasza się robotem indeksującym na serwerze, wysyłając żądania za pomocą ciągu znaków użytkownika Googlebot / 2.1 (+ http://www.googlebot.com / bot.html) . Aplikacja Node.js może sprawdzić ten ciąg agenta użytkownika w oprogramowaniu pośredniczącym i odesłać z powrotem stronę główną zoptymalizowaną dla przeszukiwacza, jeśli pasuje ciąg agenta użytkownika. W przeciwnym razie możemy normalnie obsłużyć żądanie.
Wygląda na to, że testowanie będzie skomplikowane, ponieważ nie jesteśmy właścicielami Googlebota. Jednak Google oferuje usługę do tego celu dla publicznie dostępnych witryn produkcyjnych w ramach Narzędzi dla webmasterów, ale łatwiejszym sposobem na przetestowanie jest sfałszowanie naszego ciągu znaków użytkownika. Zwykle wymagało to hackery z wiersza polecenia, ale Narzędzia dla programistów Chrome ułatwiają to, klikając przycisk i zaznaczając pole:
Otwórz Narzędzia dla programistów w Chrome, klikając przycisk z trzema poziomymi liniami po prawej stronie paska narzędzi Google, a następnie wybierając Narzędzia z menu i klikając Narzędzia dla programistów.
W prawym dolnym rogu ekranu znajduje się ikona koła zębatego: kliknij na nią i zobacz zaawansowane opcje programistyczne, takie jak wyłączenie pamięci podręcznej i włączenie rejestrowania XmlHttpRequests.
Na drugiej karcie z etykietą Zastąpienia kliknij pole wyboru obok etykiety użytkownika agenta i wybierz dowolną liczbę programów klienckich z menu rozwijanego Chrome, Firefox, IE, iPady i innych. Agent Googlebota nie jest domyślną opcją. Aby z niego skorzystać, wybierz opcję Inne i skopiuj i wklej ciąg znaków użytkownika do podanych danych wejściowych.
Teraz ta zakładka podszywa się pod Googlebota, a kiedy otworzymy dowolny URI w naszej witrynie, powinniśmy zobaczyć stronę przeszukiwacza.
W konkluzji
Oczywiście różne aplikacje będą miały różne potrzeby w odniesieniu do tego, co zrobić z robotami sieciowymi, ale zawsze jedna strona zwrócona do Googlebota prawdopodobnie nie wystarcza. Będziemy musieli również zdecydować, które strony chcemy ujawnić i udostępnić naszej aplikacji sposób mapowania URI _escaped_fragment_ = klucz = wartość do treści, którą chcemy wyświetlić.
Możesz chcieć się wymyślić i powiązać odpowiedź serwera z frameworkiem front-end, ale zazwyczaj korzystam z prostszego podejścia i tworzę własne strony dla robota i umieszczam je w osobnym pliku routera dla robotów.
Istnieje również wiele bardziej legalnych robotów indeksujących, więc gdy dostosujemy nasz serwer do robota Google, możemy go rozszerzyć, aby je uwzględnić.
Czy tworzysz strony z jedną stroną? W jaki sposób strony pojedynczych stron działają w wyszukiwarkach? Daj nam znać swoje myśli w komentarzach.
Wyróżniony obraz / miniatura, szukaj obrazu przez Shutterstock.